面向聪明小白的编程入门教程 做点有意思的东西(Part 7)
做一个文档转换器应用,虽然用不了太多代码,但是要涉及到进程、线程、自定义Qt信号等太过抽象的东西。在做这个应用前,我们还是先来点简单的吧。之前的教程好像有些无聊,这节课,我们来学着做点有意思的东西。
有意思的东西,要有有意思的内容。如果自己没有内容,就到互联网上致敬一些吧。
1. 做一个IP地址查看器
说实话,查看电脑的IP,也挺无聊的,但是够简单,所以就从这里开始吧。IP地址在操作系统里就可以直接查看。但是除了IP地址,我们也想通过IP获取地理地址和网络运营商情况。IP地址和地理地址并没有固定的关系,所以我们需要借助网络上的数据库,或者说借助第三方的服务来查询。这里,我们选用IP.CN提供的IP地址查询服务。
from PyQt5.Qt import (
QApplication,
QWidget,
QLabel,
QPushButton,
QVBoxLayout,
QSizePolicy
)
def fetch_ip():
from urllib.request import urlopen, Request
return urlopen(Request("https://ip.cn", headers={"User-Agent": "curl/7"})) \
.read().decode().strip().replace("来自", "\n来自")
app = QApplication([])
lbl = QLabel()
lbl.setStyleSheet("background: teal; color: lime; font-size: 72px;"
"qproperty-alignment: AlignCenter;"
"qproperty-text: 'Ready.'")
lbl.setSizePolicy(QSizePolicy(QSizePolicy.Ignored, QSizePolicy.Ignored))
btn = QPushButton()
btn.setStyleSheet("* { background: seagreen; color: aqua; font-size: 72px; border: none }"
"* { qproperty-text: 获取IP地址 }"
"*:hover { background: darkgreen }"
"*:pressed { background: olive }")
btn.setSizePolicy(lbl.sizePolicy())
btn.clicked.connect(lambda: lbl.setText(fetch_ip()))
box = QVBoxLayout()
box.addWidget(lbl)
box.addWidget(btn)
box.setStretch(0, 2)
box.setStretch(1, 1)
box.setSpacing(0)
box.setContentsMargins(0, 0, 0, 0)
wnd = QWidget()
wnd.setWindowTitle("IP地址察看器")
wnd.resize(777, 777 * 0.618)
wnd.setLayout(box)
wnd.show()
app.exec()
运行以上程序,点击按钮,大约卡顿半秒后,文本标签处就会显示我们电脑的IP地址、地理地址和ISP信息。
这个程序涉及到了不少新的知识点,我来依次解释一下:
def 函数名(...参数):这种语法是用来定义函数的。Lambda表达式定义的是匿名函数,def定义的是有名字的函数。函数接受0个或多个输入,处理后返回0个或多个输出。- 冒号之后的下一行开始是函数体。函数体左边的四个空格不能省略。
Python为了简洁,没有提供特殊的符号来给函数定界。Python用Tab(制表符)或空格来给函数定界。Tab在不同平台下宽度可能不一样,所以程序代码中的空白一般用空格。理论上任意个空格都可以,但使用4个空格已经是事实上的标准了。 - 函数名称里面执行的逻辑,不一定要跟函数名有关系。在函数体里头,可以执行我们想执行的任意逻辑。
- 函数体可以什么都不做。但是
Python规定函数体不能为空。所以,表示什么都不做,要用语句pass - 函数体通过
return关键字结束执行,并将return后边跟着的数据(如果有的话)返回。没有返回语句的函数,会执行到函数尾部,返回None - 用来导入模块的
import语句,除了放在代码头部外,也可以用在函数体里面。但是出了这个函数,import进来的东西就访问不到了 - Python是一种脚本语言,意思是Python代码会从头到尾一行一行地顺序执行。所以,用到的模块要提前导入,用到的函数要提前定义
- 使用Python代码也可以访问网页。Python内置的
urllib模块提供了这个功能。 - URL就是我们通常说的网址。常见的网址可能使用
http协议,也可能使用https协议。所以,在代码中,我们要明确指出 urlopen函数可以将网页下载回来。不同的网页,下载回来的格式也不一样。可能是普通的HTML网页(最常见的网页类型),可能是纯文本文档(在Windows下俗称记事本文档),也可能是图片、视频、压缩包等电脑上可以存储的任意文件格式。urlopen函数下载网页消耗的时间是不确定的。Python代码要一行一行执行,下载网页时,程序要等待下载完成才能执行其他代码(包括响应用户的点击事件)。所以,下载时会导致软件假死,点击按钮没反应。- Python语言经常被用来做爬虫(用来自动化批量下载网页),而
urllib是Python官方的可以做爬虫的模块。所以,直接使用urllib,会被ip.cn识别为爬虫而拒绝服务(返回HTTP状态码403)。所以,我们需要将我们的HTTP请求伪装成浏览器或者其他用户代理(User-Agent, 一般用户不会直接使用HTTP协议访问网页,而要借助浏览器代为访问,浏览器代理用户访问网页,这时浏览器的角色就是用户代理)。不过,我们这次不伪装成浏览器,而要伪装成cURL(可以当作一个命令行下的网页浏览器)。因为IP.CN对浏览器返回的是一个HTML网页,对cURL返回的是一个包含了IP信息的字符串。为了省却解析HTML网页获取我们关心的IP信息,我们决定伪装成cURL,一步到位获取。 - 要伪装成
cURL,我们需要修改HTTP请求的头部Header。HTTP规范定义了HTTP头部的User-Agent字段表示用户代理。我们修改这个字段即可。经过我的测试,IP.CN对cURL的识别策略是User-Agent字段以curl开头,后面跟斜杠和curl版本号。我们用curl/7就行。 urllib.request.urlopen返回的数据类型是urllib.response.Response对象,这是urllib对HTTP响应的封装。Response.read()方法可以读取响应内容。由于HTTP响应可能是张图片,所以不能用字符串来表示。read方法读到的是字节码,字节码可以表示任何数据类型,也可以表示任何文件类型。从字节码转换到字符串,需要解码,即调用decode()方法。这张,我们便得到了一个表示IP地址信息的字符串,格式类似于当前 IP: 115.171.212.227 来自: 北京市 电信\n。- 字符串调用
strip()方法可以去除首位的空白字符,比如换行符号。 - 字符串调用
replace()方法,可以替换字符串中的指定子串为其他文本。我们用replace()方法来给字符串中间添加一个换行符。 - 控件的文本、对齐方式等属性也可以通过样式表来设置,比如
qproperty-text表示文本,qproperty-alignment表示对齐方式。 - Qt的样式表(QSS, Qt Style Sheet)中,
*是通配符,表示任意控件。 QSS中,:hover表示鼠标悬浮状态,:pressed表示鼠标按下状态。- 除了
QBoxLayout.addWidget()方法,我们还可以通过QBoxLayout.setStretch(索引,比重)来调节子控件在布局中的拉伸因子。
注意,IP地址是商品,是可以用来买卖的,IP地址的归属地和归属运营商(ISP)也是动态变化的,不一定准确。
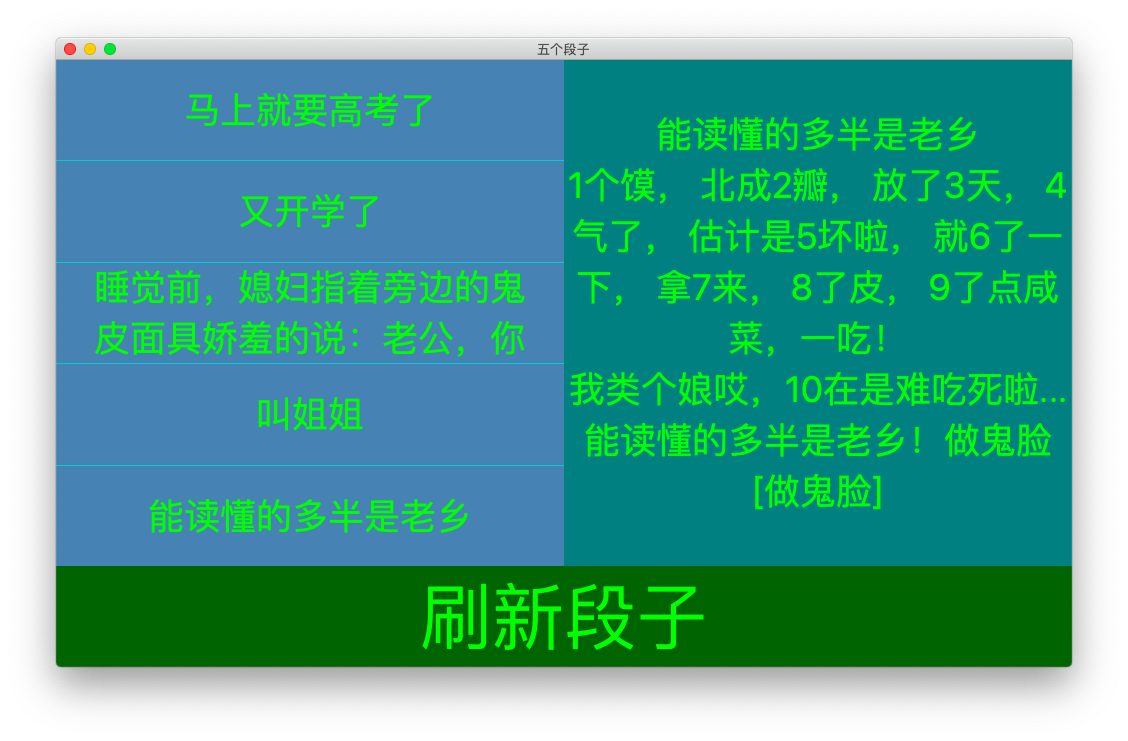
2. 看段子
我们刚做的IP地址查看器,在查询IP时会假死一会儿。这个问题比较复杂,我们留到后面处理。现在,我们该做一个看段子的软件。我们的目标是,点击按钮可以随机刷新出几条段子,点击段子名称可以阅读段子的内容。
当然,我们不是在做AI(人工智能),不过就算是做AI,要想编个能看的段子,一般的电脑CPU怕是一时半会算不出来。我们希望找一个免费的可以提供随机段子的接口。这里说的接口是HTTP接口,接口类似于运行在其他电脑上的一个远程的函数,我们可以调用这个函数(这个接口)获取我们需要的东西。接口的格式一般比较固定,里面的数据一般不会经过特殊处理,可以直接读取解析出来。
不过,免费的接口可不好找。我搜了半天也没有搜到。看来我们得自立更生,找一个可以提供随机段子的网站,将网页里的随机段子手动扒出来了。这种程序学名叫做爬虫。现在教爬虫有点过早,但是为了我们的程序有内容可看,只能先硬着头皮上了。
我发现一个网站叫段子网(此处不是在做广告,数数本文的留言人数,就知道我没骗你啦),首页每次刷新,都会在侧边栏生成5个随机的段子。不过,这5个段子只有标题。看来,我们的程序又得多几行代码了。
from PyQt5.Qt import (
QApplication,
QWidget,
QLabel,
QPushButton,
QVBoxLayout,
QSizePolicy,
QHBoxLayout
)
from urllib.request import urlopen
from parsel import Selector
import textwrap
app = QApplication([])
lbl = QLabel("Ready.")
lbl.setSizePolicy(QSizePolicy.Ignored, QSizePolicy.Ignored)
lbl.setWordWrap(True)
lbl.setStyleSheet("font-size: 36px")
btn = QPushButton("刷新段子")
lft = QVBoxLayout()
lft.setSpacing(1)
for i in range(1, 6):
wgt = QPushButton(f"段子{i}")
wgt.setStyleSheet("* { font-size: 36px; background: steelblue }"
"*:hover { background: cadetblue }")
wgt.setSizePolicy(QSizePolicy.Ignored, QSizePolicy.Ignored)
lft.addWidget(wgt)
top = QHBoxLayout()
top.addLayout(lft)
top.addWidget(lbl)
box = QVBoxLayout()
box.addLayout(top)
box.addWidget(btn)
box.setSpacing(0)
box.setContentsMargins(0, 0, 0, 0)
wnd = QWidget()
wnd.setWindowTitle("五个段子")
wnd.resize(999, 999 * 0.618)
wnd.setLayout(box)
wnd.show()
app.setStyleSheet(
"* { font-size: 72px; color: lime; background: darkturquoise }"
"QLabel { background: teal; qproperty-alignment: AlignCenter }"
"QPushButton { background: darkgreen; border: none }"
"QPushButton:hover { background: seagreen }"
"QPushButton:pressed { background: green }"
)
def fetch_joke(url):
htm = urlopen(url).read().decode()
title = Selector(htm).xpath("//article//h1/text()").get()
content = "\n".join(Selector(htm).xpath("//article/section/p/text()").getall())
return f"{title}\n{content}"
def refresh_jokes():
htm = urlopen("https://duanziwang.com").read().decode()
jks = [x.attrib for x in Selector(htm).xpath("//div/li/a")]
for idx, jok in enumerate(jks):
btn: QPushButton = lft.itemAt(idx).widget()
btn.setText(textwrap.fill(jok["title"][:24], 12))
btn.setProperty("url", jok["href"])
btn.clicked.connect(lambda: lbl.setText(fetch_joke(app.sender().property("url"))))
btn.clicked.connect(refresh_jokes)
app.exec()
执行以上代码,可以看到我们的段子软件的功能已经完成。这个程序涉及到了不少新的知识点,我大概解释一下:
QApplication.setStyleSheet可以设置应用的全局样式表QLabel.setWordWrap可以启用或禁用自动换行(默认关闭状态)for x in y这种语法是用来遍历容器类型数据(比如列表)的。y是容器,x是元素,在每次迭代中会更新。range(a, b)函数可以用来生成整数范围[a, b-1]。范围不是列表,不存储元素,只是描述了元素的生成规则。for也可以用来遍历迭代器。range函数返回的范围属于Python中的迭代器。- 在函数中定义的变量是局部变量,出了函数就访问不到了。要在函数体中定义或访问全局变量,得用
global关键字 - 点击不同的段子标题,要下载不同的段子。所以,我们需要在槽函数里获知被点击的段子。我们考虑将段子的网址保存到按钮中,在槽函数中只要考虑如何获取哪个按钮被点击就行了。
Qt不会将点击事件的信号源(按钮对象)传递给槽函数,但是,Qt提供了QObject.sender()实例方法来获取最新的信号源。 - 这个
QObject.sender()是个实例方法,意思是这个方法只能在QObject类的实例对象上调用。 QObject是Qt系统中所有类型的根类。Qt中的所有类都继承自QObject。所以,每个Qt中的对象都是QObject类的对象QObject.sender()方法可以在任意Qt对象上调用。我们可以直接用app.sender()来获得最新的信号源,即用户最新点击的按钮。QObject.setProperty可以在Qt对象上保存数据。比如,我们可以将段子的地址保存在关联的按钮中。textwrap.fill方法可以以指定的段长切割字符串,每个切点放一个换行符- 常见的网页是一种HTML文档,是一种基于标签的树形结构,格式类似于
<html><head></head><body><a href="www.github.io">CLICK</a></body></html>。手动解析这种文档,一般要用到正则表达式,非常麻烦。所以,我们一般用现成的解析器来解析HTML文档。在这里,我们使用parsel(pip install parsel)这个模块来解析HTML。 Selector(HTML代码)构造函数用来生成HTML解析器,Selector.xpath()方法用指定的路径(XPath)来解析HTML,返回的对象还是Selector。Selector.get方法获取匹配到的第一个元素,Selector.getall方法获取匹配到的全部元素。//div/li/a表示HTML文档中任意位置的div标签下的直接子li标签下的直接子a标签。在我们下载的网页中,这个XPath语句正好匹配到我们需要的5个段子的超链接。要获取标签的文本,需要使用text()。[function(x) for x in y]这种语法叫生成器,可以用来将一个列表中的元素经过处理一一映射到另一个列表。我们也可以利用这种语法,将需要写两行的for x in y: function(x)语法压缩到一行。"\n".join(字符串列表)这种语法可以用特定的字符连接多个字符串。
最后附截图一张: